The dataset used for TREC 2017 Dynamic Domain Track consists of two domains: Ebola and New York Times.
1.1 Ebola
The Ebola dataset is crawled by Juliana Friere (NYU, juliana dot freire at nyu dot edu), Kien Pham(NYU),
Peter Landwehr (Giant Oak, peter dot landwehr at giantoak dot com) and Lewis McGibbney (JPL, Lewis dot J
dot Mcgibbney at jpl dor nasa dot gov).
The Ebola dataset contains records related to the Ebola outbreak in Africa in 2014-2015.
The original dataset includes tweets relating to the outbreak, web pages from sites hosted in the
affected countries as well as PDF documents from websites such as World Health Organization,
Financial Tracking Service and The World Bank.
Such information resources are designed to provide information to citizens and aid workers on the ground.
1.2 New York Times
The New York Times dataset is published by Evan Sandhaus in 2008 under LDC Catalog No.
LDC2008T19.
The New York Times dataset consists of articles published in New York Times from January 1, 1987
to June 19, 2007 with metadata provided by the New York Times Newsroom, the New York Times Indexing Service
and the online production staff at nytimes.com. Most articles are manually summarized and tagged by professional staffs.
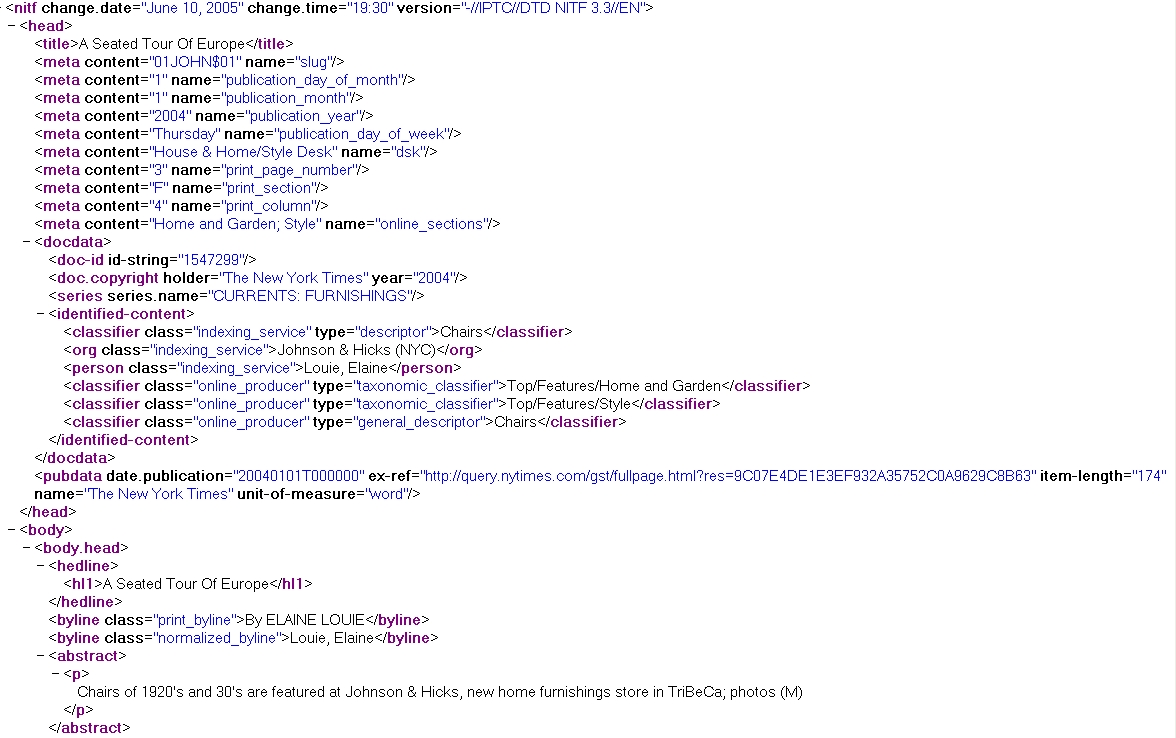
The original form of this dataset is in
News Industry Text Format (NITF). This dataset can aid the
research in Document Categorization, Information Retrieval, Entity Extraction and etc.
1.3 Dataset Statistics
The details of these two datasets are shown in Table 1.
Table 1 Datasets Statistics
| Datasets |
Compressed Size |
Uncompressed Size |
Number of Documents |
Original Format |
| Ebola |
1.5 GB |
9.5 GB |
194,481 |
html, tweet, PDF |
| New York Times |
3.1 GB |
16 GB |
1,855,658 |
NITF |
All the released data will be in TRECTEXT format.
<DOC>
<DOCNO>document_number</DOCNO>
<TEXT> original_content </TEXT>
</DOC>
The
document_number is a globally unique id across all the datasets. The
original_content
is the document content in the original format. That is, if the document is from Ebola dataset, then its
original_content is usually in html format (
sample) ;
if the document is from New York Times dataset, then
its
original_content is in
NITF
(
sample).
This section provides instructions about gaining the access to the corpus data. For topics, you will need
to obtain it from
TREC(NIST).
3.1 Ebola
To get access to the collections, you must be a TREC 2017 participant. Complete the
TREC DD
Organizational User Agreement (password protected, use the TREC participant password) and email it
as a scanned PDF or a high-quality digital photo to Angela (dot) Ellis (at) NIST (dot) gov, including
your TREC participant ID. Within a week you should receive access credentials to download the data.
Local users of the data must complete the
Individual
User Agreement and return it to the organizational point of contact who will maintain those records.
3.2 New York Times
You can only get access to the New York Times dataset through
LDC.
Most universities and research institutions hold a LDC license. You may want to contact your own institution
first regarding the access first. Besides that, we also provide scripts (enclosed in Jig) uncompress and transform the format of the original file,
which may help you build your own index.

{kind=link}
{kind=link}