In order to take part in the DD track, you need to be a registered participant of TREC. The TREC Call for
Participation, at
http://trec.nist.gov/pubs/call2017.html, includes
instructions on how to register.
The datasets and relevance judgments will be made generally available to non-participants after the TREC
2017 cycle, in February 2018. So register to participate if you want early access.
The TREC DD track provides interesting and understudied domains of documents. In 2017, we provides two
datasets, Ebola and New York Times, from different domains.
The Ebola dataset contains webpages, tweets and
other records related to the Ebola outbreak in Africa from 2014 to 2015. Documents in this dataset are
crawled from internet and most of them are in html format.
The New York Times dataset contains articles published in New York Times from 1987 to 2007.
Documents in this dataset are manually organized and annotated. All the documents in this dataset are stored
in
NITF.
Please check
Datasets page for more details.
Within each domain, there will be 25-50 topics that represent user search needs.
The topics have been developed by the NIST assessors in a period of three weeks.
A topic (which is like a query) contains a few words. It is the main
search target for one complete run of dynamic search. Each topic contains multiple subtopics, each of which
addresses one aspect of the topic. The NIST assessors have tried (very hard to) produce a complete set of
subtopics for each topic, and so we will treat them as the complete set and use them in the interactions and
evaluation.
An example topic from the 2015 Illicit Goods domain topic set may be found
here. It is about "paying for amazon book reviews" and contains
2 subtopics.
The topics will be made available from the
Tracks page
in the TREC Active Participants area. You cannot access this page without registering for TREC. If you
lose your active participants password, you will need to contact
trec@nist.gov.
The topics file contains not only the queries but in fact the full ground truth data: subtopics, relevant
documents, and highlighted passages.
DO NOT READ THE FILE. The file should be used only as input to
the jig, and your system receives the truth data via the jig. If you examine the topics file, your run
may
not be labeled automatic but rather is a manual run.
When your "run" starts, your system will communicate with the jig via a simple API. Your system indicates
that it is ready for a new query, and the jig will give you a query along with its domain label. Your system
can use that query to search the domain collection and return up to five documents to the jig. The jig will
reply with relevance information for any of those retrieved documents that have been judged.
Your systems will receive an initial query for each topic, where the query is two to four words and
additionally indicates the domain by a number 1, 2, 3 or 4. In response to that query, systems may return up
to five documents to the user. The jig (acting as a simulated user) will respond by indicating which of the
retrieved documents are relevant to their interests in the topic, and to which subtopic the document is
relevant to. Additionally, the simulated user will identify passages from the relevant documents and assign
the passages to the subtopics with a graded relevance rating. The system may then return another five
documents for more feedback. Systems should stop until they believe they have covered all the user's
subtopics sufficiently.
The subtopics are not known to your system in advance; systems must discover the subtopics from the user's
responses.
The jig only gives relevance information when it exists. If the jig gives no information about a document
your system retrieved, it does not mean that the document is not relevant, it means that the user hasn't
examined it. Your system should assume this partial relevance situation,
NOT the traditional TREC
interpretation that unjudged documents are not relevant.
The following picture illustrates the task:
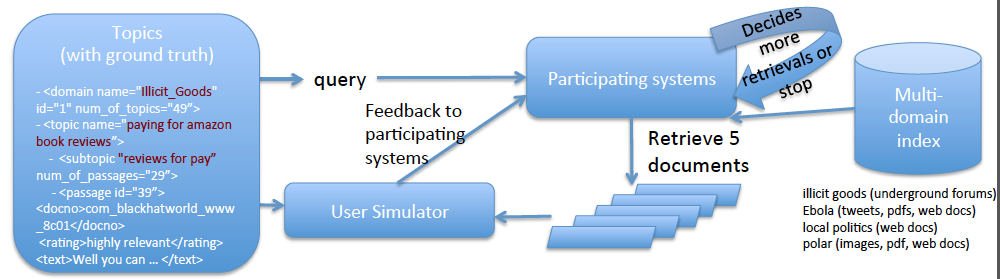
The system's interactions with the user can be simulated by a jig that the track coordinators provide. This
jig runs on Linux, Mac OS, and Windows. You will need the
topics with ground truth to make the jig work, and
your system may only interact with the ground truth through the jig that we provide.
You can find the jig program
here.
The measurements of runs are Cube Test, sDCG and Expected Utility. Scoring scripts are included in the jig.
other diagnostic measures such as precision and recall may also be reported.
Cube Test is a search effectiveness measurement evaluating the speed of gaining relevant information (could
be documents or passages) in a dynamic search process. It measures the amount of relevant information a
system could gather and the time needed in the entire search process. The higher the Cube Test score, the
better the IR system.
sDCG extends the classic DCG to a search session which consists of multiple iterations. The relevance scores
of results that are ranked lower or returned in later iterations get more discounts. The discounted cumulative
relevance score is the final results of this metric.
Expected Utility scores different runs by measuring the relevant information a system found and the length
of documents. The relevance scores of documents are discounted based on ranking order and novelty. The document
length is discounted only based on ranking position. The difference between the cumulative relevance score and
the aggregated document length is the final score of each run.
References:
Jiyun Luo, Christopher Wing, Hui Yang, and Marti Hearst. 2013.
The water lling model and the cube
test: multi-dimensional evaluation for professional search. In Proceedings of the 22nd ACM international
conference on Information & Knowledge Management. ACM, 709-714.
Kalervo J�rvelin, Susan L Price, Lois ML Delcambre, and Marianne Lykke Nielsen. 2008.
Discounted cumulated gain based
evaluation of multiple-query IR sessions. In European Conference on Information Retrieval. Springer, 4-15.
Yiming Yang and Abhimanyu Lad. 2009.
Modeling expected utility of
multi-session information distillation. In Conference on the Theory of Information Retrieval. Springer,
164-175.
In TREC, a "run" is the output of a search system over all topics. In the DD track, the runs are the output
of the harness jig. Participating groups typically submit more than one run corresponding to different
parameter settings or algorithmic choices. The maximum number of runs allowed for DD-2017 is
five
from each team.
We use a line-oriented format similar to the classic TREC submission format:
topic_id docno ranking_score on_topic subtopic_rels
where 'on_topic' is 1 or 0 if the document is relevant to any subtopic, and the subtopic_rels indicate
graded relevance for the document for all relevant subtopics. For instance:
topic_id docno ranking_score on_topic subtopic_rels
DD15-1 2322120460-d6783cba6ad386f4444dcc2679637e0b 883.000000 1 DD15-1.1:3|DD15-1.4:2|DD15-1.4:2|DD15-1.4:2|DD15-1.4:2|DD15-1.4:2|DD15-1.2:2|DD15-1.2:2
DD15-1 1322509200-f67659162ce908cc510881a6b6eabc8b 564.000000 1 DD15-1.1:3
DD15-1 1321860780-f9c69177db43b0f810ce03c822576c5c 177.000000 1 DD15-1.1:3
DD15-1 1320503040-e8c92486dc3462e4a352c4fd41d3a723 66.000000 0
DD15-1 1327908780-d9ad76f0947e2acd79cba3acd5f449f7 25.000000 1 DD15-1.3:2|DD15-1.1:2
Participants are expected to submit at least one run by the deadline.
Runs may be fully automatic, or manual. Manual indicates intervention by a person at any stage of the
retrieval. We welcome unusual approaches to the task including human-in-the-loop searching, as this helps us
set upper performance bounds.
